Scrapy是一套開放原始碼的框架,提供多種工具從Web網站擷取資料,主要應用於資料量較大、邏輯處理較複雜的網頁爬取。除了可以剖析與爬取網頁資料外,它還可以發送請求、 處理和儲存成指定的檔案格式、偵錯等等多項功能,方便我們運用與管理所需要的資料。
開啟 Anaconda Prompt命令提示字元後輸入安裝指令
conda install -c conda-forge scrapy
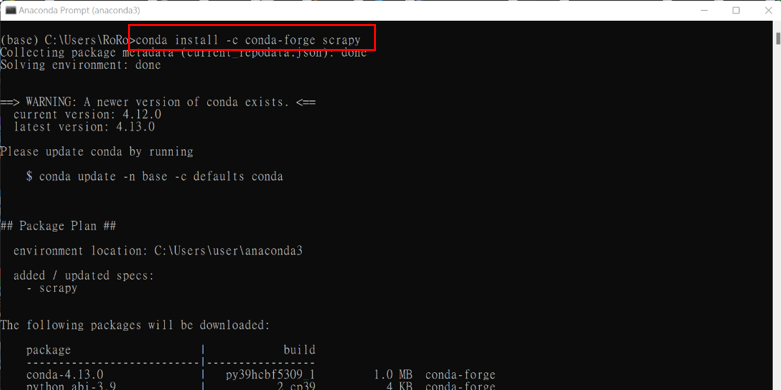
輸入y鍵確認下載與安裝套件及完成安裝
開啟 Anaconda Prompt命令提示字元並輸入指令啟動Scrapy Shell
scrapy shell
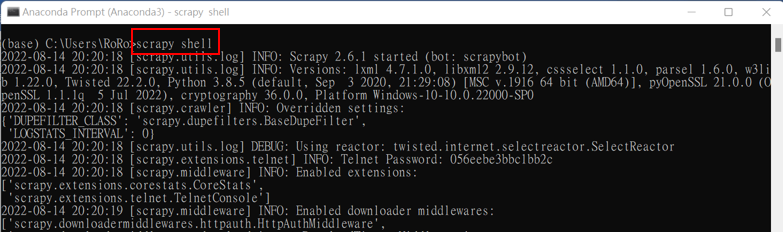
使用下方指令下載指定的網頁網址,實作練習以批踢踢實業坊中的股票版網址為例
fetch(“網頁網址”)
若回應資訊出現DEBUG: Crawled (200)代表成功下載指定網址
使用下方指令顯示下載的網頁內容
view(response)

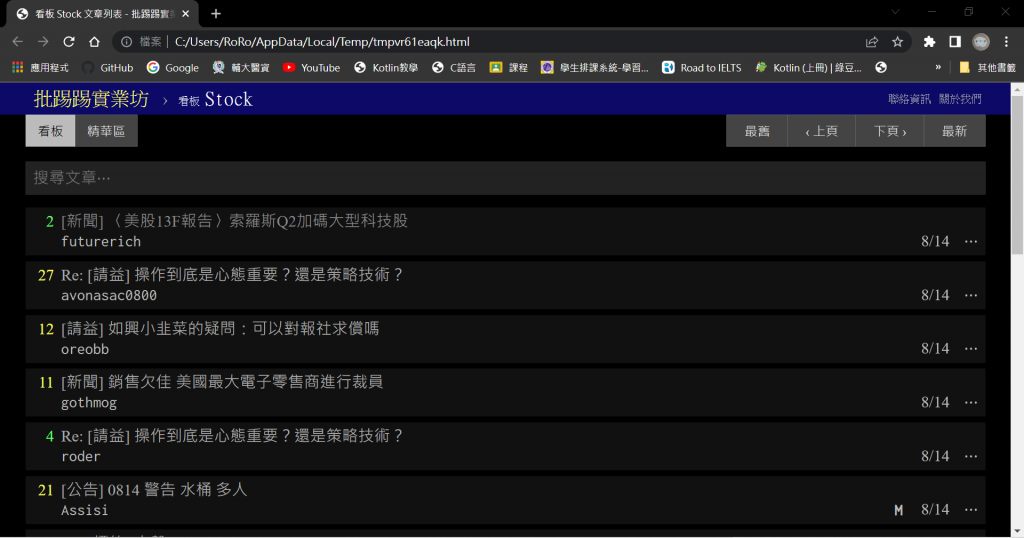
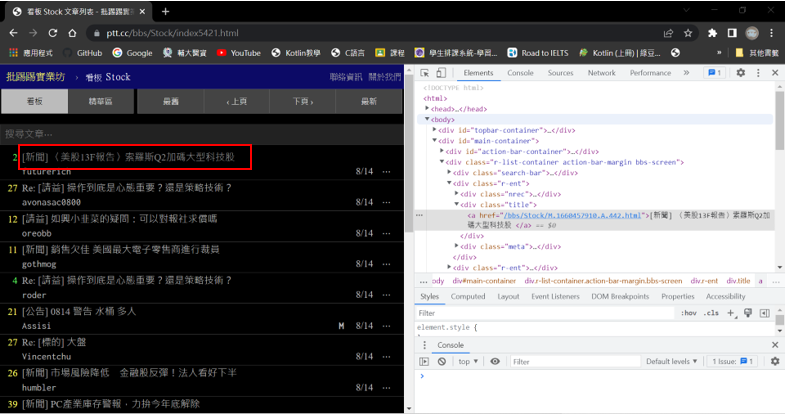
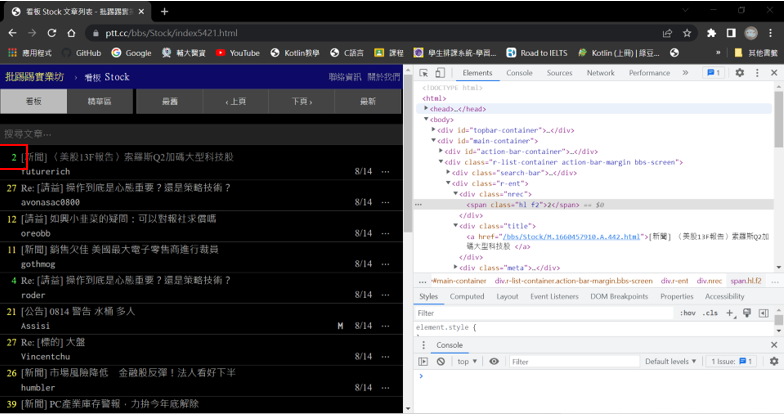
定位要擷取的資料並取得
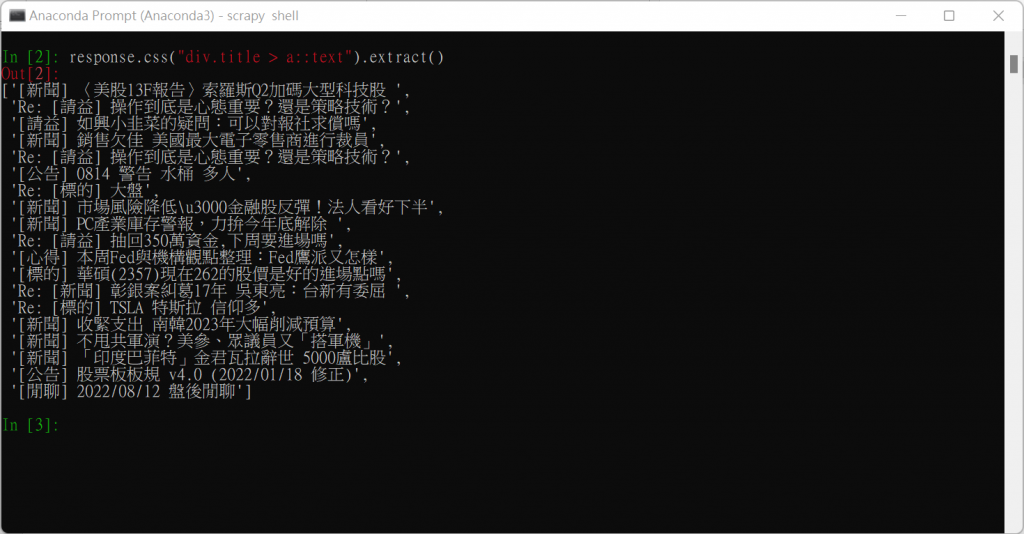
(1) CSS選擇器: 取得全部文章標題
response.css("以css表示的資料位置").extract()
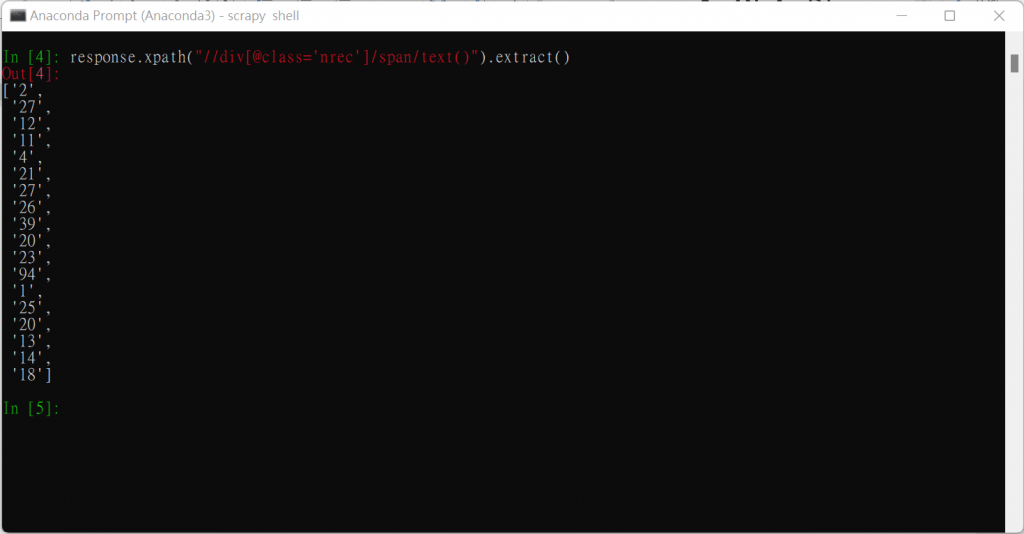
(2) XPath表達式: 取得全部發文的推文數
response.xpath("以xpath表示的資料位置").extract()


 iThome鐵人賽
iThome鐵人賽